FLOR is a folksonomy enrichment algorithm that automatically enriches user-generated folksonomy tags by reusing existing Knowledge Sources (such as online ontologies indexed in the Watson Semantic Web Gateway and WordNet) and not requiring training data. FLOR's input is a folksonomy tagspace of user generated tags and the output is a semantic layer describing the concepts of these tags and their relations.
For example, consider the following image* from Flickr which is a photo of the Balaton Lake in Hungary. The resource is tagged with {Hungary, Balaton�,Europe}. FLOR takes as input the tagset of resource 16668 and generates a semantic layer that describes the meaning of each of the resource's tags. In bold white you can see the meaning of the tags (sense of a tag) and in faded white the additional information that exists for a respective sense in the various knowledge sources used.
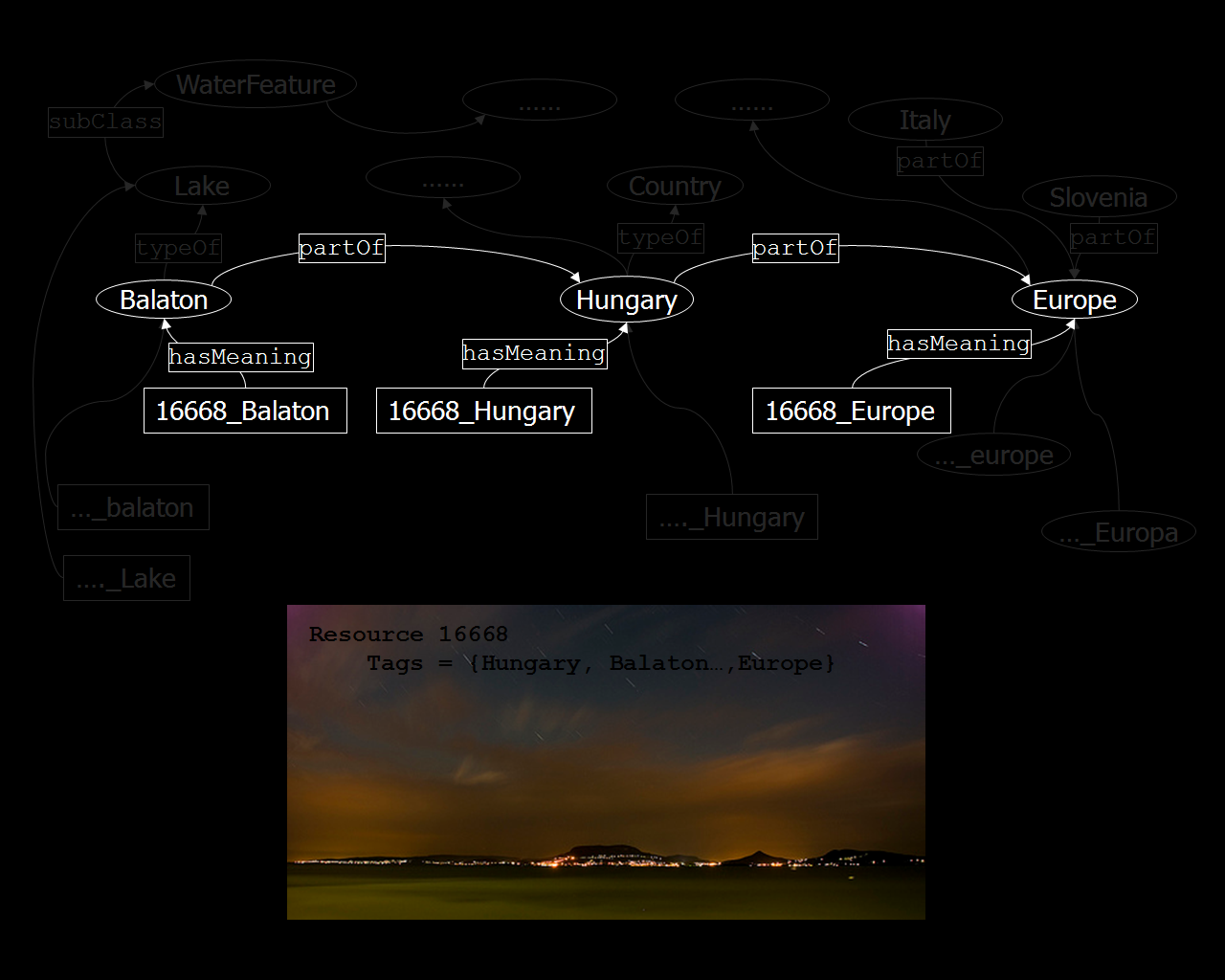 We can see that this semantic layer integrates the semantics discovered for this resource with the semantics generated for other resources. E.g. we can see that apart from Hungary, Italy and Slovenia are also parts of Europe. In addition, tags from other resources ..._Europa are have the same meaning as 16668_Europe.
We can see that this semantic layer integrates the semantics discovered for this resource with the semantics generated for other resources. E.g. we can see that apart from Hungary, Italy and Slovenia are also parts of Europe. In addition, tags from other resources ..._Europa are have the same meaning as 16668_Europe.
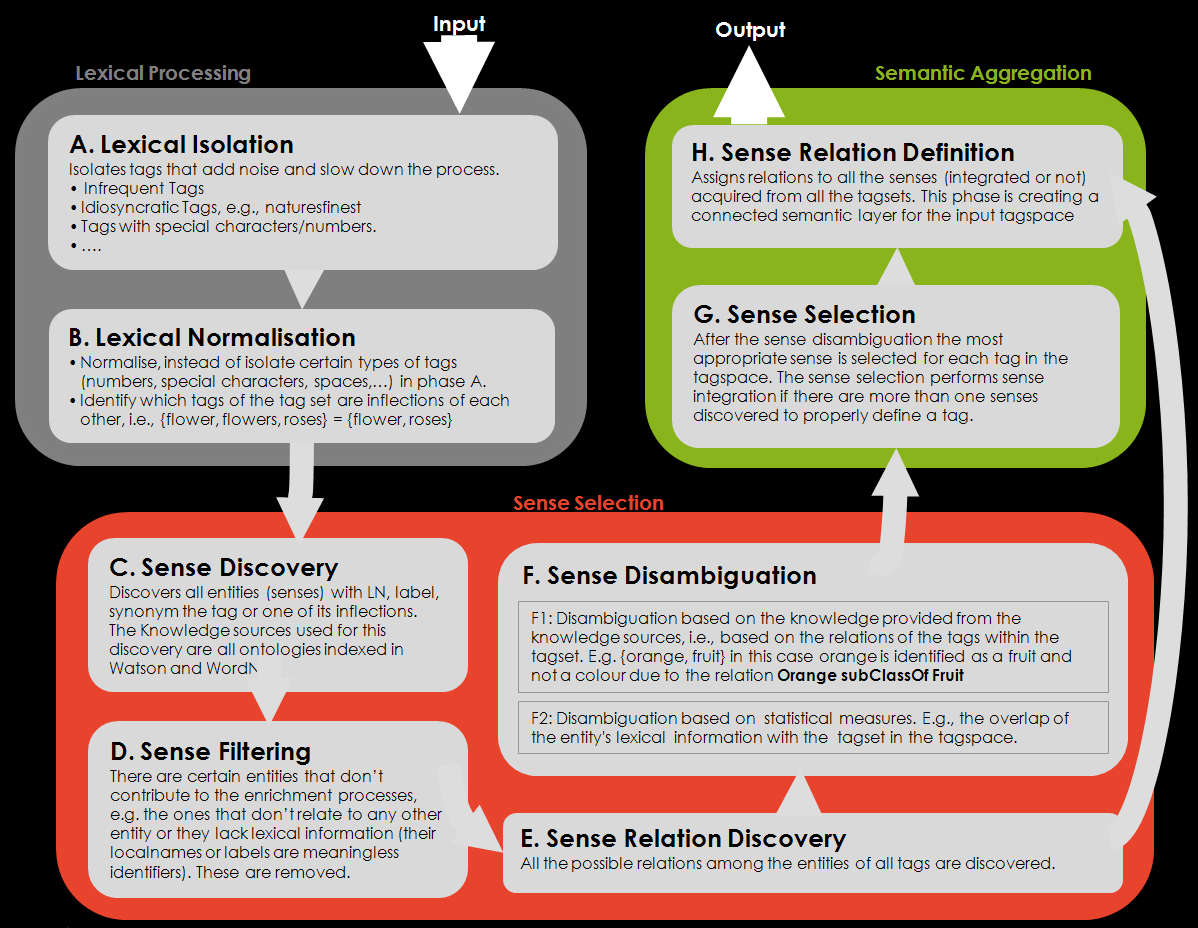
To transform the flat description of resources to a rich semantic structure FLOR performs in the following three essential phases. Because, the FLOR enrichment process is modular and can be altered to support different use cases, each of the phases can be executed in more steps (A-H). For example the phase of Lexical Processing removes from each tagset the tags that the following phases of FLOR can't process (A.) and generates a list of syntactic equivalents for each tag (B). For example, step A removes the tags that don't contribute to the current enrichment process. E.g., the idiosyncratic tags (that make sense only to a tagger or a group of taggers). In each enrichment case the requirements for isolation or normalisation of tags are changing, as a result different processess need to be defined for certain specific cases. The FLOR api implements the basic functions that are most commonly used to isolate tags such as tags with special characters, with numbers, infrequent/idiosyncratic tags e.t.c.
Equally the phase of Sense Selection finds all possible available senses for the tags, filters them according to the requirements of the case, selects candidate senses for the tags and disambiguates them. Finally the Semantic Aggregation bring all the semantic discovered in the previous phase together and returns the semantic layer that describes the input tagspace.
* This image has been selected from the The MIRFLICKR-25000 Image Collection that has been used to perform experiments with FLOR. Refer to the publications section for more details.
This is the second and improved version of the FLOR algorithm. To see a description of a previous FLOR version click here.